Компания анонсировала внедрение нейросетевой архитектуры, которая станет усовершенствованным принципом ранжирования. Как отметило руководство, это самый значимый прорыв в этом направлении за последнее десятилетие.
Но многих пользователей интересует суть изменений, ведь многие предпочитают заблаговременно подготовиться к инновациям.
Что это такое?
Дословно это Yet Another Transformer with Improvements – еще один преобразователь с улучшениями. Нейро-архитектура позволяет оценить взаимосвязь между запросом и содержанием. Физически это очень дорогое оборудование, в которой толстая шина объединяет GPU карточки в единую плату. Серверы при этом расположены близко друг другу, стойками. Визуально это выглядит так:

Обучение происходило по достаточно простому методу – система сопоставляла запросы и документы, на которых пользователи задерживались максимально долго или после которых прекращали серфить. Это привело к формированию эталонов, для этого была проделана огромная работа по сопоставлению вопросов и ответов, содержимого и пр. Поэтому в разряд эталонов попадают только документы, полностью удовлетворяющие списку требований, и прошедшие экспертизу ботов. На основе эталонов и работает нейросетевая архитектура.
Но разработчики не стали на этом останавливаться – они обучили ее предугадывать экспертную оценку, что привело к появлению нового способа ранжирования.
После окончания обучения было проведено множество тестов, которые дали рекордно высокие показатели.
Что кроется в деталях?
Рассматривая подробнее принцип действия, становится понятно, что YATI оценивает каждую страницу, ищет релевантную информацию. При этом, как и раньше, учитываются ключевики. Разница теперь заключается в том, что Яндекс рассчитывает число совпадающих слов или протяженность самой длинной присутствующей интерпретации.
Еще один параметр – данные о факторах поведения. Чем больше переходов по линку, тем вероятнее, что здесь находится ответ.
Симбиоз этих показателей показал высокую эффективность.
Поэтому один из наиболее эффективных способов продвижения после обновления – улучшение сниппетов. Для этого стоит проанализировать конкурентов, выбрать наиболее удачные предложения, на основе которых сделать собственный проект и реализовать его. Для анализа можно использовать сервис MegaIndex.
Что касается системы подсчета количества вхождений, то здесь заложено несколько десятков формул, для каждой из которых установлен собственный коэффициент. Полученные по ним значения суммируются, чем выше полученное число, тем выше вероятность нахождения ответа на заданный пользователем вопрос.
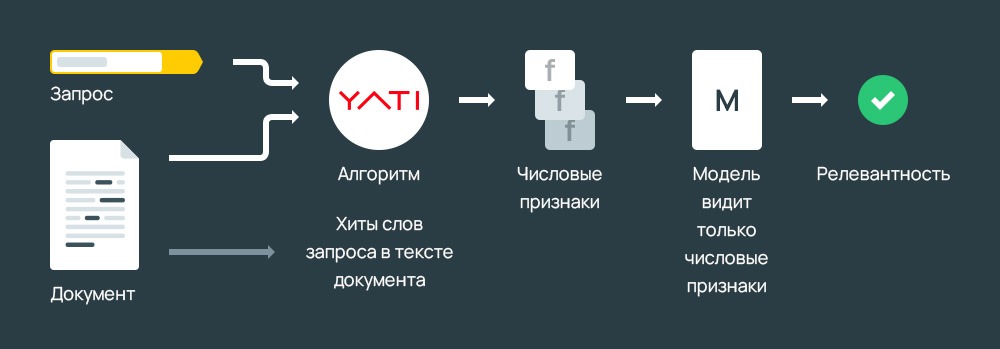
Но разработчики пошли дальше и внедрили новую фишку:
- помимо заданных юзером выражений включаются синонимы;
- на основании этого появляются предложения с другими ключами, по которым можно перейти с главной.
Для примера: читатель вводит – отдых на Кавказе, боты предлагают – путешествие по знаковым местам Кавказа; нужен ли загранпаспорт для поездки в Абхазию.
Чтобы найти подобное, используется множество способов, в том числе лого. Теоретически выдача не будет отличаться, т.к. это синонимичные фразы, которые будут учитываться в обоих случаях.
Таким образом, нужно расширять семантику, выбирая максимум синонимов, анализируя стримы. В них входят весь текстовый контент со входящих ссылок или вопросов, для которых юзеры находят здесь результат. Они также учитываются алгоритмом, поэтому пренебрегать ими нельзя. Это дополнительный плюс, но не главный, т.к. большинство из них стали не актуальными из-за спама.
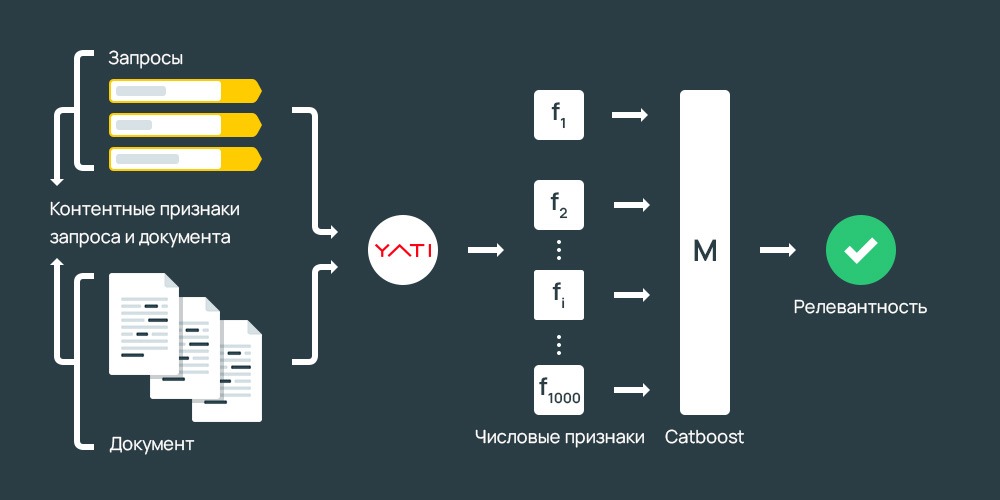
Для работы используется специальное древо, закономерности действия которого основаны на вышеуказанных формулах, алгоритмах, каждый из которых имеет коэффициент значимости. На их основании определяется наличие семантической связи, но не суть.
Что изменилось в работе нейросетей?
Первоначально принцип заключался в следующем:
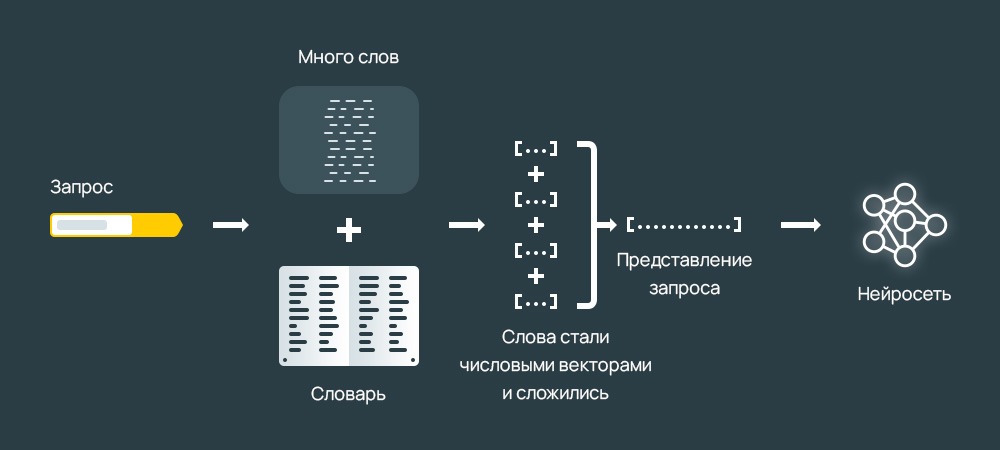
- слова превращались в векторы;
- они суммировались в один, представляющий весь текст, но с произвольным порядком;
- ограниченный размер словаря, в котором нет поиска по похожим мловам, а буквы меняют порядок для нахождения наиболее точного отражения буквенной сути – например, из «колонна» можно получить «локон», «кол», «лоно», «наклон» и т.д., все они участвовали в поиске;
- прохождение через несколько плотных слоев нейронов, отсеивающих «мусор» для выделения семантического вектора.
Таким образом, можно было определять даже сложные взаимосвязи, рассчитывая кратчайшее расстояние между ними.
Сейчас же суть изменилась – системный продукт постоянно самообучается. Таргетом служит выбор читателя, который определяется по логам. Формально, это оценивание поведенческих факторов – сколько пробыл читатель на страничке, совершил ли целевое действие, прекратил ли после этого искать и т.д. На основании этого YATI решает, есть ли тут нужная информация.
При этом производится анализ «положительных» результатов, а отрицательные найти намного сложнее. То есть отсутствие целевого клика не является признаком низкокачественного контента.
По сравнению с предшественником нейронная сеть способна оперировать текстом любого размера, при этом не составляя вектор ограниченной длины. У нее нет такой высокой вероятности ошибки или погрешности. Например, результат может находиться в разных частях документа, новый алгоритм это оценит, а старый – отсеет. Предшественник больше подходит для коротких высказываний и пр.
В основу новшества все же легли проверенные технологии, но в более совершенной форме. После этого его дообучили на более современных технологиях, что дало максимальный эффект за десятилетие. Суть заключается в опирании на простые примеры, после которых происходит дообучение – усовершенствование для повышения точности.
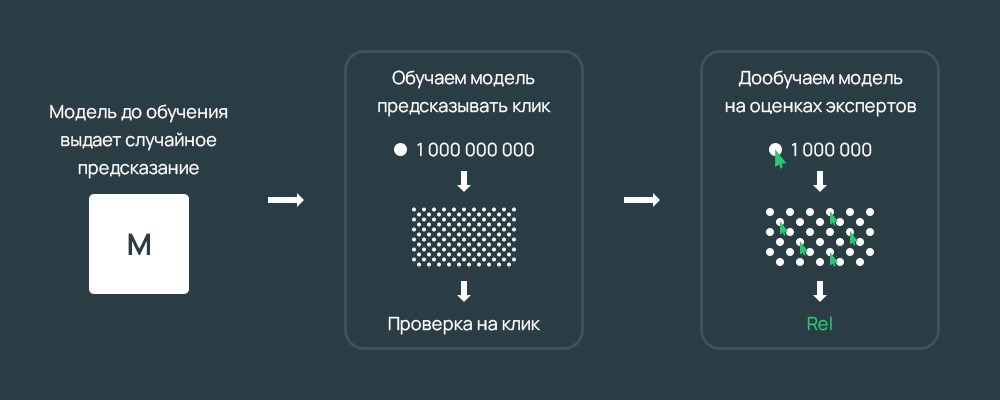
Нейросети-трансформеры
Это уже следующий уровень развития, который уже успешно реализован IT-гигантом. В сетях с архитектурой трансформеров текст:
- это отдельный вектор;
- анализируется отдельно;
- не меняет положения слов.
Элементом считаются и знаки препинания, частота символов.
В технологии реализован механизм внимания, который обеспечивает концентрацию на отдельных фрагментах. Таким образом, в интернет-магазине будет в основном учтена только информация, интересующая покупателя, остальной контент учитывается с меньшим коэффициентом. То есть оценивается только часть страницы.
Учится она так:
- Распознавание особенностей языка, текстовых материалов, предсказание перехода.
- Дополнительный анализ оценок.
- Ознакомление с оценками асессоров.
- Итоговая метрика, объединяющая эти параметры.
При этом учитываются те же составляющие, что и раньше:
- текстовое наполнение;
- фрагменты странички (не целиком) – содержание, заголовки и прочие составляющие;
- стримы.
Тяжелые модели затратны в реализации, поэтому Яндекс перешел на боле простые, пародирующие тяжелые. При этом тренировка происходит в оффлайн, качество практически не меняется, но скорость снижается. Чтобы избавиться от этого недостатка, IT-компания разделила процессы на онлайн и оффлайн, что уменьшило нагрузку и увеличило скорость. После этого обе составляющих объединяются.
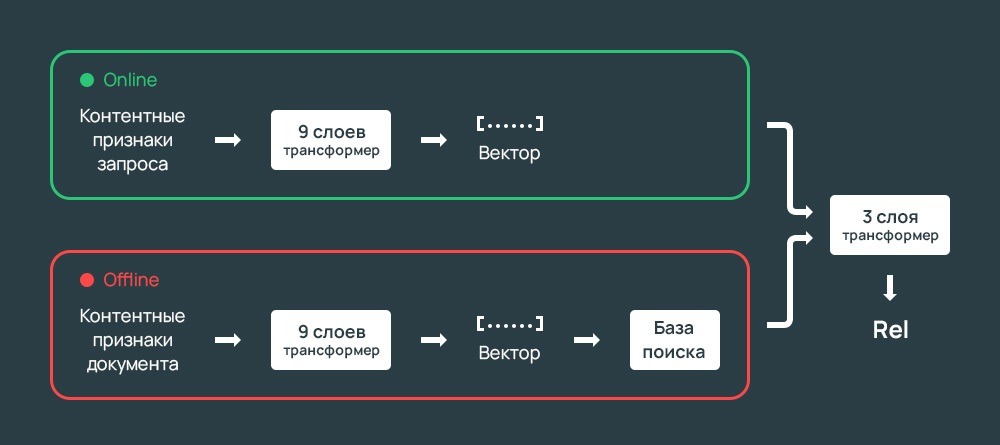
YATI и SEO
По мере развития трафик будет перетекать от небольших порталов, работающих преимущественно по низкочастотным запросам, к крупным площадкам.
Важные нюансы
- Если на портале мало интересных страниц, это снижает его релевантность.
Модель способна распознавать ресурс, как единое целое. Наличие некачественного наполнения повлечет падение рейтинга.
- Обязательные Н1, Н2.
Учитывается структура странички, разметка, а также структура самой статьи. Поэтому важно использовать блоки, информативные заголовки, можно заложить явную разметку. Для 10 предложений этого не требуется, но более крупные фрагменты лучше разбить на мелкие.
- Сегментация помогает выбрать данные, подаваемые в поисковик.
Это позволяет выделить участки, которые будут оценены моделью. Для заголовков это достаточно важно, ведь их индекс рассчитывается по специальной формуле и влияет на предсказание.
- Переиндексация.
Чтобы оценить все ресурсы, потребуется повторная индексация. Если содержимое не менялось, то в выдаче ничего не изменится.
Как подготовить ресурс?
Связь в семантике основана не только на ключах, но и на синонимах, поэтому следует формировать расширенное семантическое ядро. И вместо количества контента сфокусироваться на качестве (не по объему, а по количеству вкладок сайта и полезного на них).
Для этого эксперты предлагают:
- расширить СЯ релевантными фразами (также можно использовать MegaIndex – бесплатно);
- проанализировать источники трафика, в соответствии с ними добавить релевантные выражения;
- учесть поисковые подсказки, внедрить их;
- проверить логи внутреннего поиска.
Выводы
Система Yet Another Transformer with Improvements анализирует содержимое блоками, сопоставляя суть поискового поля и наполнения сайта. При этом он эффективно работает как с короткими выражениями, так и длинными вложениями, определяет значимые блоки, учитывает контекст и порядок. Поэтому мы рекомендуем владельцам сайтов:
- повысить качество контента, учесть стримы и синонимичные фразы;
- разбить страничку на сегменты, выделить структуру, что поможет проще анализировать ее.
Больше интересного о крупных IT-компаниях читайте здесь.


